🤔Azure Data Factory Series: Mastering the Self-Hosted Integration Runtime🤔
на канале: JBSWiki
Introduction 🎥
Welcome to the Azure Data Factory Series! In this episode, we’re diving deep into the world of the Self-Hosted Integration Runtime (SHIR). This powerful tool is essential for connecting your on-premises data to the Azure cloud, enabling seamless data integration across your hybrid environments.
Whether you're a seasoned data engineer or just starting with Azure Data Factory (ADF), this video will guide you through everything you need to know about SHIR, from its setup and configuration to the advantages and disadvantages of using it. We’ll cover best practices, troubleshooting tips, and real-world scenarios where SHIR can significantly enhance your data workflows. Plus, we’ll explore some common challenges and how to overcome them.
What is the Self-Hosted Integration Runtime (SHIR)? 🤔
The Self-Hosted Integration Runtime is a key component in Azure Data Factory that enables secure data movement and transformation across on-premises and cloud environments. It’s a software that you install on your local machine or server to create a bridge between your on-premises data sources and the Azure cloud.
Here’s a closer look at what SHIR is and how it works:
Data Movement: SHIR facilitates the transfer of data from your on-premises sources (like SQL Server, Oracle, or flat files) to Azure services such as Azure Blob Storage or Azure SQL Database.
Data Transformation: In addition to moving data, SHIR can also perform data transformation tasks. This means you can process and modify data as it moves from your on-premises environment to the cloud.
Secure Connectivity: One of the most important aspects of SHIR is its ability to connect to on-premises data sources securely. It ensures that your data remains protected during the transfer process, adhering to your organization’s security policies.
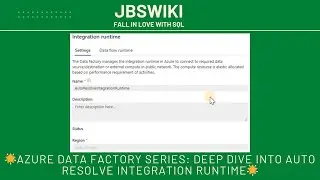
Setting Up the Self-Hosted Integration Runtime 🔧
Setting up SHIR is straightforward, but it’s essential to follow each step carefully to ensure that your data integration process is smooth and efficient.
Step 1: Download and Install SHIR 💾
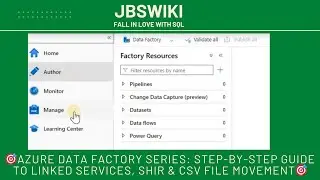
Access the Azure Data Factory Portal:
Navigate to your Azure Data Factory instance in the Azure portal.
In the left-hand menu, select Integration Runtimes under the Manage section.
Click on + New to create a new Integration Runtime.
Choose the SHIR Option:
When prompted, select Self-Hosted as the type of Integration Runtime you want to create.
Provide a name for your SHIR and click Create.
Download the SHIR Installer:
Once the SHIR creation process begins, you’ll be prompted to download the installation file.
Download the installer to the machine that will host the SHIR.
Run the Installer:
Execute the installer and follow the on-screen instructions.
During installation, you’ll need to authenticate the SHIR with your Azure subscription. This ensures that the SHIR is securely connected to your Azure Data Factory instance.
Step 2: Configure SHIR ⚙️
After installation, you’ll need to configure your SHIR to connect with your on-premises data sources and Azure services.
Register Your SHIR:
In the Azure portal, you’ll see a key that’s generated during the SHIR creation process. This key is used to register the SHIR with your Azure Data Factory.
Enter the key in the SHIR configuration interface on your local machine.
Set Up Connectivity:
Define the on-premises data sources that SHIR will connect to. This might include databases, file systems, or other data services within your organization’s network.
Ensure that the SHIR has the necessary network permissions to access these data sources. This might involve configuring firewall rules or proxy settings.
Test the Connection:
Before you start using SHIR in your data pipelines, it’s crucial to test the connection to your on-premises data sources.
Use the testing tools provided in the SHIR interface to ensure that the connectivity is working as expected.
Step 3: Integrate SHIR into Your Data Pipelines 📊
With SHIR set up and configured, you can now start using it in your Azure Data Factory pipelines.
Conclusion 🎬
The Self-Hosted Integration Runtime (SHIR) is a powerful tool that enables secure and efficient data integration between on-premises environments and the Azure cloud. By following best practices for deployment, performance optimization, security, and monitoring, you can get the most out of SHIR and ensure that your data integration workflows run smoothly.
In this video, we’ve covered everything you need to know about SHIR, from setup and configuration to the advantages and disadvantages of using it. We’ve also provided tips and best practices to help you optimize your SHIR setup and overcome common challenges.
If you found this video helpful, please give it a thumbs up and subscribe to our channel for more in-depth tutorials and tips. Your support helps us continue to bring you the best content on Azure Data Factory and other cloud technologies.

![[FREE] SLIMESITO x BEEZYB TYPE BEAT 2022 -](https://images.videosashka.com/watch/1EoTITwenvE)