🌠Azure Data Factory Series: Data Lakes, Lakehouses, and Beyond🌠
Welcome to our latest installment in the Azure Data Factory Series, where we delve into the evolving world of data management! 🌍 In this video, we’ll take you on a comprehensive journey through the concepts of data lakes, lakehouses, and how they fit into the broader landscape of modern data architecture. Whether you're a seasoned data engineer, a data scientist, or just someone curious about the latest trends in data storage and processing, this video is packed with insights just for you! 💡
1️⃣ The Evolution of Data: From Structured to Unstructured 📊➡️📂
We begin by exploring the shift in how data is handled. In traditional setups, organizations primarily dealt with structured data 🗂️—think of databases where every piece of information fits neatly into tables with rows and columns. Tools like SQL Server, SSIS, and BCP were the go-to solutions for managing and processing this structured data, transforming it, joining tables, and loading it into data warehouses from where reports were generated. These processes were scheduled at intervals that met the organization’s needs, such as hourly or daily.
2️⃣ Understanding Data Lakes: The New Age Storage Solution 🌊
As we deal with increasingly diverse data formats, traditional data warehouses are no longer sufficient. This is where data lakes come into play. In the second segment, we'll demystify the concept of data lakes. 🌊
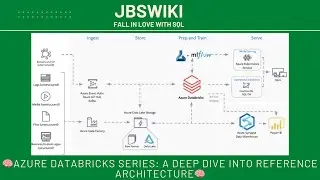
A data lake is essentially a vast storage repository that can hold a large amount of raw data in its native format until it is needed for analysis. It’s the single source of truth 🛑 where you can store structured, unstructured, and semi-structured data together. This section will highlight how data lakes can accommodate data from various sources, such as Oracle, Postgres, DB2, flat files, and more.
When I first heard about data lakes, I thought they were complex and intimidating. 💭 However, at its core, a data lake is simply a storage account where you can save any type of file. Because it stores all necessary files, it is referred to as a data lake. You'll discover how these storage solutions can integrate data from different systems into one unified source, simplifying access and analysis.
3️⃣ Introducing the Data Lakehouse: Marrying Data Lakes and Warehouses 🏠
Next, we move on to the concept of a data lakehouse. This is where things get exciting! 🎉 A data lakehouse combines the best of both worlds—the storage flexibility of data lakes and the data management capabilities of traditional data warehouses. This hybrid approach allows for both large-scale data storage and the implementation of ACID (Atomicity, Consistency, Isolation, Durability) properties, enabling reliable transaction processing and complex data operations.
We’ll explore how adding metadata 📝, governance 📚, and ensuring ACID compliance transforms a simple data lake into a powerful data lakehouse. This section will cover the technical nuances that allow for scalable, secure, and performant data processing across varied data formats.
4️⃣ The Roles in Data Management: Data Scientists, Data Engineers, and Data Analysts 👩💻👨💻
In any discussion about data, it’s crucial to understand the roles of the key players involved in managing and utilizing that data. In this part of the video, we’ll break down the differences between data scientists, data engineers, and data analysts, each playing a vital role in the data lifecycle.
Data Scientists 🔍 use statistics and machine learning models to predict outcomes and answer critical business questions. They require skills in mathematical formulas 🧮, programming 👩💻, and statistics 📊.
Data Engineers 🛠️ build and optimize the systems that allow data scientists and analysts to perform their work. Their expertise lies in programming, big data, and cloud technologies ☁️.
Data Analysts 📈 utilize the systems created by data engineers to analyze data and communicate the results to drive business decisions. They need strong communication skills and business acumen 💼.
This section will also discuss where I fit into the picture as a data engineer. I focus on supporting existing setups, leveraging my knowledge in SQL, cloud computing, distributed systems, and a bit of Python programming 🐍 to ensure that the data pipelines and systems run smoothly.
9️⃣ Conclusion: Embracing the Data-Driven Future 💼
As we wrap up this video, we’ll reflect on the key takeaways and the importance of staying adaptable in a rapidly changing data landscape. Whether you’re building the systems as a data engineer, analyzing the data as a data scientist, or using the insights as a data analyst, embracing these technologies will be crucial for success in the data-driven future. 🌟
Thank you for joining us on this journey through Data Lakes, Lakehouses, and Beyond! 🚀 Don’t forget to like, share, and subscribe for more insightful content from our Azure Data Factory Series. We’d love to hear your thoughts and questions, so feel free to drop a comment below! 💬

![[AMV] верно, я Кира..](https://images.videosashka.com/watch/8-3v0E_Axvw)