🎯Azure Data Factory Series: Step-by-Step Guide to Linked Services, SHIR & CSV File Movement🎯
Welcome to our Azure Data Factory Series! 🎉 In today's video, we're embarking on a hands-on journey through Azure Data Factory (ADF), one of the most powerful and versatile tools in the Microsoft Azure ecosystem. ADF empowers businesses to create and orchestrate data-driven workflows in the cloud. Whether you're migrating data from on-premises systems to the cloud, integrating various data sources, or transforming data for analytics, ADF has you covered.
In this tutorial, we'll dive deep into three essential components of ADF:
Linked Services 🔗: Establishing connections to various data stores and compute services.
Self-hosted Integration Runtime (SHIR) 🖥️: Enabling data movement and transformation across different environments.
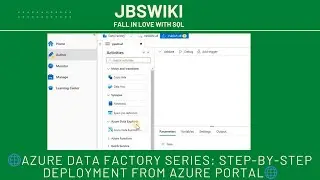
ADF Pipelines 🚜: Designing and executing data-driven workflows, including moving a CSV file from one container to another.
By the end of this video, you'll have a solid understanding of how to deploy Linked Services, set up SHIR, and create a fully functional ADF Pipeline to move data across containers—all within the Azure portal. Let's dive in! 🎯
1. Introduction to Azure Data Factory 🌟
Azure Data Factory (ADF) is a cloud-based data integration service that allows you to create data-driven workflows for orchestrating and automating data movement and data transformation. Here’s a brief overview of why ADF is a go-to solution for data professionals:
Scalability 📈: Handle massive volumes of data effortlessly.
Flexibility 🔄: Integrate data from various sources, whether on-premises or in the cloud.
Cost-Effective 💸: Pay only for what you use, with no upfront costs.
Rich Integration 🔗: Seamlessly connect with a wide range of Azure services, databases, and external platforms.
ADF's primary components include Pipelines, Datasets, Activities, Triggers, Linked Services, and Integration Runtimes. In this video, we'll focus on Linked Services, SHIR, and Pipelines, guiding you step-by-step through the process of setting them up in the Azure portal.
2. Deploying Linked Services in Azure Data Factory 🔗
What Are Linked Services? 🤔
In ADF, Linked Services are much like connection strings in traditional databases. They define the connection details for data sources and compute environments that ADF interacts with. Linked Services can connect to a variety of data stores such as Azure Blob Storage, SQL Server, or external services like Amazon S3 or even on-premises databases.
Why Are Linked Services Important? 🌍
Linked Services are foundational because they allow ADF to access and interact with the data stored in different environments. Without them, ADF wouldn't know where your data resides or how to connect to it.
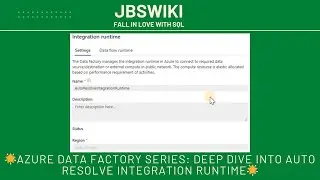
Step-by-Step Guide to Deploy Linked Services 📝
Log into the Azure Portal 🌐: Navigate to https://portal.azure.com and sign in with your Azure account.
Navigate to Azure Data Factory 🏗️: Use the search bar to find "Data Factory" and click on it.
Create a New Data Factory Instance 🆕:
Click on "Create Data Factory" and provide necessary details such as Subscription, Resource Group, and Region.
Name your Data Factory instance and click on "Review + Create".
After validation, click on "Create" to deploy your Data Factory.
Access the Data Factory Studio 🎛️: Once deployed, navigate to "Author & Monitor" to access the ADF Studio.
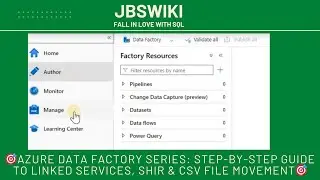
Create a Linked Service 🧩:
In the ADF Studio, click on "Manage" from the left-hand panel.
Under "Connections," select "Linked Services" and click on "New".
Choose the type of data store you want to connect to (e.g., Azure Blob Storage, Azure SQL Database).
Provide the necessary connection details such as account name, key, or connection string.
Test the connection to ensure it’s working, then click "Create".
Use Cases for Linked Services 🎯
Cloud Storage: Connect to Azure Blob Storage for storing and retrieving large datasets.
On-Premises Databases: Securely connect to on-prem databases using SHIR (discussed next).
Third-Party Data Sources: Integrate with external data sources like Amazon S3, or Google BigQuery.
By setting up Linked Services, you've established the foundation that allows ADF to interact with various data sources. Next, we’ll set up the Self-hosted Integration Runtime (SHIR) to enable data movement between these sources.
3. Setting Up Self-hosted Integration Runtime (SHIR) 🖥️
What is SHIR? 🤔
The Self-hosted Integration Runtime (SHIR) is a component of ADF that allows you to securely connect your on-premises data sources to ADF.
If you found this tutorial helpful, don’t forget to like, share, and subscribe for more in-depth Azure Data Factory tutorials! Hit the notification bell 🔔 so you never miss an update. Feel free to leave your questions or feedback in the comments below—we’d love to hear from you!
Thank you for joining us in this Azure Data Factory Series! We hope this guide has equipped you with the knowledge and confidence to harness the full power of ADF in your data integration projects. Until next time, happy data engineering! 🎉