Lesson 5: Principles of Data Science by Mohammad Hajiaghayi: Basic Statistics and ML Algorithms
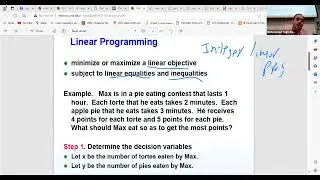
In this session, we discuss basic statistics and ML algorithms. The discussion so far has covered the foundational aspects of data science, including an introduction and motivation for the field, as well as basic tools like probability theory, linear programming, and network X. These fundamental concepts serve as building blocks for solving various problems, underscoring their versatility and applicability across different domains. Today, we're delving deeper into statistics, a vital component of data science, particularly in areas like AB testing, which is essential in the realm of big tech. Understanding statistical concepts like correlation and causation is crucial, as they form the basis for making informed decisions in data analysis. Additionally, we're touching upon basic machine learning (ML) algorithms, laying the groundwork for more in-depth exploration in future courses.
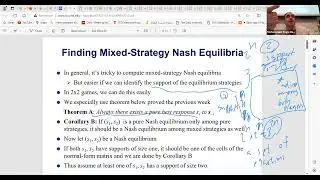
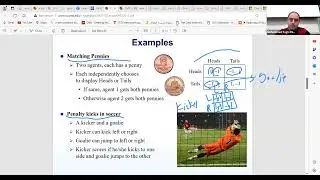
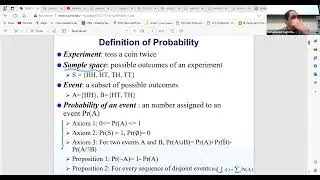
In our discussion on statistics, we're distinguishing between different types of data, such as quantitative and categorical, and exploring concepts like population versus sample. Moreover, we're introducing machine learning, which has deep roots in statistics, and discussing its relevance in modern data science. The notion of an "Oracle," representing a source of data samples, highlights the practical challenges of working with large datasets. Furthermore, we're touching upon inferential statistics, which bridges the gap between traditional statistics and machine learning, offering insights into range values and distribution characteristics.
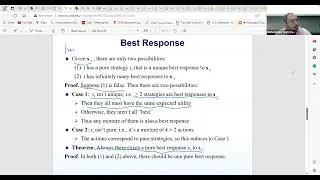
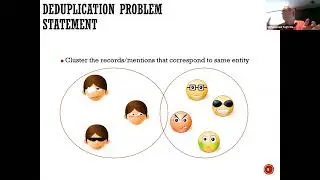
As we delve further into machine learning, we're exploring various algorithms and their applications. From supervised learning to unsupervised learning, each approach offers unique insights and solutions to different problems. Concepts like clustering and classification are fundamental to understanding how ML algorithms organize and interpret data. We're also addressing the concept of hyperparameters, such as the number of trees in a random forest model, and discussing methods for optimizing model performance while mitigating issues like overfitting. Finally, we're emphasizing the importance of the bias-variance tradeoff in model selection, highlighting the need for balanced performance to ensure accurate predictions on new data.
In conclusion, our discussion has covered essential concepts in both statistics and machine learning, providing a solid foundation for further exploration in data science. By understanding these principles, students can apply them effectively to various projects and real-world scenarios. As we continue our journey in data science, we'll delve deeper into advanced topics and methodologies, equipping ourselves with the tools and knowledge needed to tackle complex challenges in the field.
#DataScience, #Statistics, #MachineLearning,#QuantitativeData #CategoricalData, #PopulationVsSample, #InferentialStatistics, #MachineLearningAlgorithms, #SupervisedLearning, #UnsupervisedLearning, #Clustering, #Classification, #Hyperparameters, #Overfitting, #FoundationalConcepts, #DataAnalysis ,#practicalapplications, #ContinuousLearning.



![Star Citizen - Making Money with an Aurora [GIVEAWAY]](https://images.videosashka.com/watch/o7JyUhfZ3Wo)