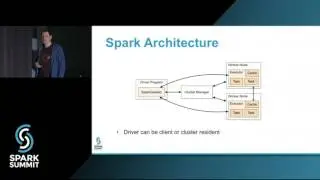
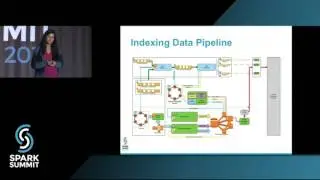
Apache Carbondata: An Indexed Columnar File Format for Interactive Query by Jacky Li/Jihong Ma
Realtime analytics over large datasets has become an increasing wide-spread demand, over the past several years, Hadoop ecosystem has been continuously evolving, even complex queries over large datasets can be realized in an interactive fashion with distributed processing framework like Apache Spark, new paradigm of efficient storage were introduced as well to facilitate data processing framework, such as Apache Parquet, ORC provide fast scan over columnar data format, and Apache Hbase offers fast ingest and millisecond scale random access.
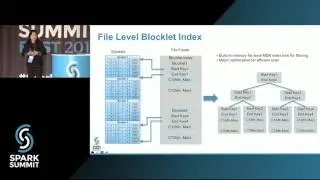
In this talk, we will outline Apache Carbondata, a new addition to open source Hadoop ecosystem which is an indexed columnar file format aimed for bridging the gap to fully enable real-time analytics abilities. It has been deeply integrated with Spark SQL and enables dramatic acceleration of query processing by leveraging efficient encoding/compression and effective predicate push down through Carbondata’s multi-level index technique.

![[FREE] SLIMESITO x BEEZYB TYPE BEAT 2022 -](https://images.videosashka.com/watch/1EoTITwenvE)