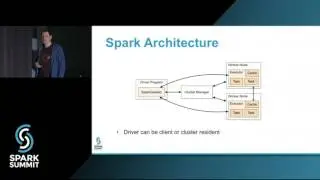
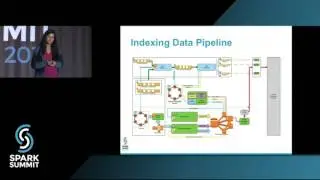
Lambda Processing for Near Real Time Search Indexing at WalmartLabs: talk by Snehal Nagmote
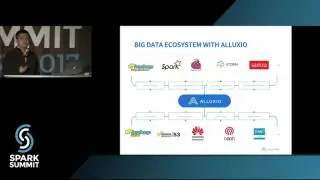
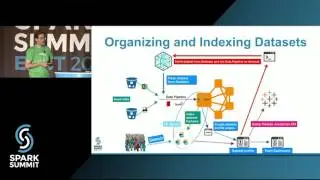
At WalmartLabs, millions of product information and new products are getting ingested every day. In quest of providing a seamless shopping experience for our customers, we developed near real time indexing data pipeline. Our pipeline is a key component to update dynamically changing product catalog and other features such as store and online availability, offers etc.
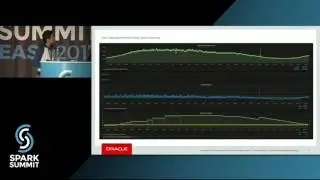
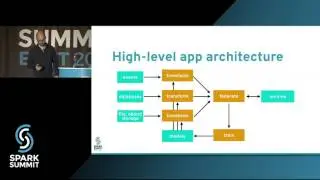
Our indexing component, which is based on Spark Streaming Receiver Approach, consumes events from multiple Kafka topics such as Product Change, Store Availability, and Offer Change and merges the transformed Product Attributes with the historical signals computed by relevance data pipeline stored in Cassandra. This data is further processed by another Streaming component, which partitions documents into Kafka topic for every shard as it can be indexed into Apache Solr for Product Search. Deployment of this pipeline is automated end to end.