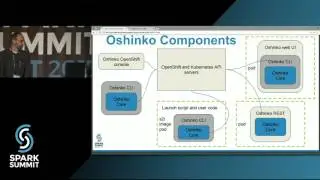
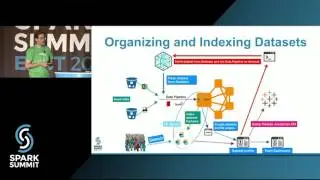
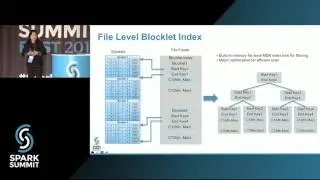
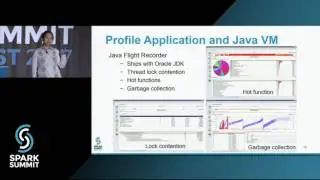
Fault Tolerance in Spark: Lessons Learned from Production: Spark Summit East talk by Jose Soltren
Spark is by its nature very fault tolerant. However, faults, and application failures, can and do happen, in production at scale.
In this talk, we’ll discuss the nuts and bolts of fault tolerance in Spark.
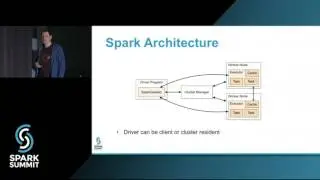
We will begin with a brief overview of the sorts of fault tolerance offered, and lead into a deep dive of the internals of fault tolerance. This will include a discussion of Spark on YARN, scheduling, and resource allocation.
We will then spend some time on a case study and discussing some tools used to find and verify fault tolerance issues. Our case study comes from a customer who experienced an application outage that was root caused to a scheduler bug. We discuss the analysis we did to reach this conclusion and the work that we did to reproduce it locally. We highlight some of the techniques used to simulate faults and find bugs.
At the end, we’ll discuss some future directions for fault tolerance improvements in Spark, such as scheduler and checkpointing changes.