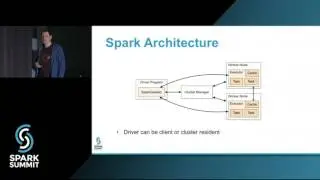
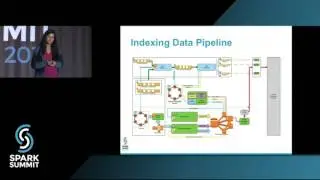
Keeping Spark on Track: Productionizing Spark for ETL: talk by Kyle Pistor and Miklos Christine
ETL is the first phase when building a big data processing platform. Data is available from various sources and formats, and transforming the data into a compact binary format (Parquet, ORC, etc.) allows Apache Spark to process it in the most efficient manner. In this talk, we will discuss common issues and best practices for speeding up your ETL workflows, handling dirty data, and debugging tips for identifying errors.