Learnings Using Spark Streaming and DataFrames for Walmart Search: by Nirmal Sharma and Yan Zheng
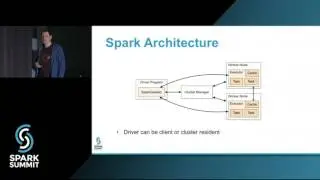
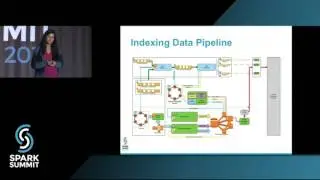
In this presentation, we are going to talk about the state of the art infrastructure we have established at Walmart Labs for the Search product using Spark Streaming and DataFrames. First, we have been able to successfully use multiple micro batch spark streaming pipelines to update and process information like product availability, pick up today etc. along with updating our product catalog information in our search index to up to 10,000 kafka events per sec in near real-time. Earlier, all the product catalog changes in the index had a 24 hour delay, using Spark Streaming we have made it possible to see these changes in near real-time. This addition has provided a great boost to the business by giving the end-costumers instant access to features likes availability of a product, store pick up, etc.
Second, we have built a scalable anomaly detection framework purely using Spark Data Frames that is being used by our data pipelines to detect abnormality in search data. Anomaly detection is an important problem not only in the search domain but also many domains such as performance monitoring, fraud detection, etc. During this, we realized that not only are Spark DataFrames able to process information faster but also are more flexible to work with. One could write hive like queries, pig like code, UDFs, UDAFs, python like code etc. all at the same place very easily and can build DataFrame template which can be used and reused by multiple teams effectively. We believe that if implemented correctly Spark Data Frames can potentially replace hive/pig in big data space and have the potential of becoming unified data language.
We conclude that Spark Streaming and Data Frames are the key to processing extremely large streams of data in real-time with ease of use.