ETL | AWS Lambda | Amazon Redshift | DynamoDB Event-driven ETL To Amazon Redshift Using AWS Lambda
===================================================================
1. SUBSCRIBE FOR MORE LEARNING :
/ @cloudquicklabs
===================================================================
2. CLOUD QUICK LABS - CHANNEL MEMBERSHIP FOR MORE BENEFITS :
/ @cloudquicklabs
===================================================================
3. BUY ME A COFFEE AS A TOKEN OF APPRECIATION :
https://www.buymeacoffee.com/cloudqui...
===================================================================
Title: Amazon DynamoDB Event Driven ETL Pipeline Using AWS Lambda and Amazon Redshift Serverless
Detailed Explanation:
1. Overview:
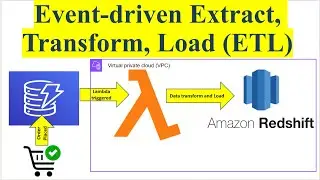
The video focuses on constructing an ETL (Extract, Transform, Load) pipeline that reacts to changes in an Amazon DynamoDB table. The pipeline utilizes AWS Lambda and Amazon Redshift Serverless to efficiently process and analyze data.
2. Components:
Amazon DynamoDB: A fully managed NoSQL database service that provides fast and predictable performance. It is used here as the source of data.
AWS Lambda: A serverless compute service that automatically manages the compute resources needed to run code. It is used to handle events from DynamoDB and process data.
Amazon Redshift Serverless: A managed data warehousing service that automatically scales to accommodate varying workloads. It is used to store and analyze the data after processing.
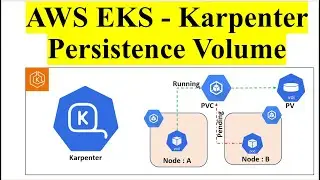
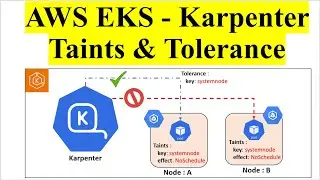
3. Architecture:
DynamoDB Table: The data source where information is stored and updated.
Event-Driven Triggers: DynamoDB streams capture changes (inserts, updates, deletes) to the table and trigger AWS Lambda functions.
AWS Lambda Functions: These are triggered by DynamoDB events. They perform various tasks, including extracting relevant data from DynamoDB, transforming it as needed (e.g., data formatting, enrichment), and then loading it into Redshift Serverless.
Amazon Redshift Serverless: Serves as the data warehouse where the processed data is stored. Users can run complex queries and analytics on this data without managing the infrastructure.
4. Workflow:
Event Capture: DynamoDB Streams capture changes made to the data in the table. These changes are sent as events.
Lambda Function Trigger: When an event is captured, it triggers a Lambda function. The function processes the event, performing the necessary data transformations.
Data Loading: After transformation, the Lambda function loads the data into an Amazon Redshift Serverless cluster.
Data Analysis: Users can then query the data in Redshift Serverless using SQL to perform analysis and generate insights.
5. Benefits:
Scalability: The serverless nature of Lambda and Redshift Serverless allows the pipeline to handle varying data volumes without manual intervention.
Real-Time Processing: The event-driven approach ensures that changes in DynamoDB are processed in near real-time.
Cost-Efficiency: Using serverless services reduces the need for managing infrastructure, and you pay only for the resources you use.
6. Practical Implementation:
The video likely includes:
Configuration Steps: How to set up DynamoDB Streams, create and configure AWS Lambda functions, and configure Amazon Redshift Serverless.
Code Samples: Examples of Lambda function code for data processing and loading.
Best Practices: Tips on optimizing the pipeline for performance and cost.
Repo Link : https://github.com/RekhuGopal/PythonH...
#etl
#aws
#awslambda
#redshift
#cloudquicklabs
#amazon
#dynamodb
#aws
#lambda
#redshift
#serverless
#etl
#datapipeline
#cloudcomputing
#awsservices
#eventdriven
#nosql
#dataanalysis
#bigdata
#awsarchitecture
#clouddata
#dataengineering
#serverlesscomputing
#awscloud
#datawarehouse
#transformdata
#eventstreaming