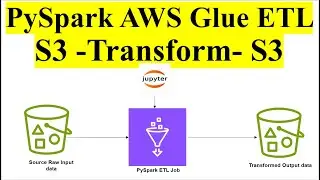
ETL PySpark Job | AWS Glue Spark ETL Job | Extract Transform Load from Amazon S3 to S3 Bucket
===================================================================
1. SUBSCRIBE FOR MORE LEARNING :
/ @cloudquicklabs
===================================================================
2. CLOUD QUICK LABS - CHANNEL MEMBERSHIP FOR MORE BENEFITS :
/ @cloudquicklabs
===================================================================
3. BUY ME A COFFEE AS A TOKEN OF APPRECIATION :
https://www.buymeacoffee.com/cloudqui...
===================================================================
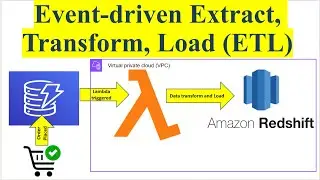
Introduction to ETL and PySpark: The video may begin with an introduction to the concepts of ETL and PySpark. ETL is a process of extracting data from various sources, transforming it into a desired format, and loading it into a target destination. PySpark is a Python API for Apache Spark, a powerful distributed computing engine.
Overview of AWS Glue: The video could provide an overview of AWS Glue, a fully managed ETL service provided by Amazon Web Services. AWS Glue simplifies the process of building, running, and monitoring ETL jobs.
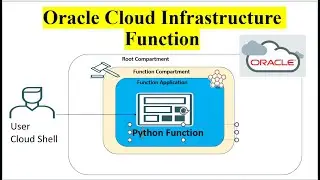
Setting Up AWS Environment: The presenter might demonstrate how to set up the AWS environment, including creating an AWS account, configuring IAM (Identity and Access Management) roles, and setting permissions for accessing S3 buckets.
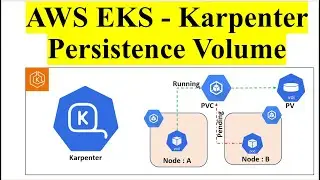
Creating an ETL Job in AWS Glue: The main part of the video would focus on creating an ETL job in AWS Glue using PySpark. This involves defining the data source (Amazon S3 bucket), specifying the transformations to be applied using PySpark code, and defining the target destination (another S3 bucket).
Writing PySpark Code: The video may include writing PySpark code to perform various transformations on the data. This could include tasks such as filtering records, aggregating data, joining datasets, or applying custom business logic.
Configuring Job Settings: The presenter might demonstrate how to configure job settings such as the type and size of the AWS Glue job, the frequency of job runs, and the monitoring options.
Running and Monitoring the Job: Once the ETL job is configured, the video would demonstrate how to run the job and monitor its progress. AWS Glue provides built-in monitoring and logging capabilities to track the status of ETL jobs and troubleshoot any issues that arise.
Testing and Validation: The presenter may emphasize the importance of testing and validating the ETL job to ensure that it is working correctly and producing the expected results. This could involve running sample data through the job and verifying the output.
Conclusion and Next Steps: Finally, the video would conclude with a summary of the key points covered and suggestions for further learning or exploration, such as additional AWS Glue features, advanced PySpark techniques, or best practices for ETL development.
Overall, the video aims to provide a comprehensive tutorial on building ETL jobs using PySpark within AWS Glue, catering to both beginners and experienced users looking to leverage the power of cloud-based ETL services for their data integration needs.
Repo link : https://github.com/RekhuGopal/PythonH...
#etl #pyspark #aws #glue #dataengineering #datalake #dataintegration #cloudcomputing #bigdata #s3 #spark #datatransformation #dataanalysis #awscloud #awsarchitecture #awsdata #awsetl #awsanalytics #awsbigdata #datamanagement #dataengineeringtutorial

![[FREE] SLIMESITO x BEEZYB TYPE BEAT 2022 -](https://images.videosashka.com/watch/1EoTITwenvE)