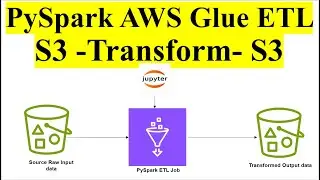
ETL | AWS Glue | AWS S3 | Transformations | AWS Glue ETL Data Pipeline With Advanced Transformations
===================================================================
1. SUBSCRIBE FOR MORE LEARNING :
/ @cloudquicklabs
===================================================================
2. CLOUD QUICK LABS - CHANNEL MEMBERSHIP FOR MORE BENEFITS :
/ @cloudquicklabs
===================================================================
3. BUY ME A COFFEE AS A TOKEN OF APPRECIATION :
https://www.buymeacoffee.com/cloudqui...
===================================================================
Title: AWS Glue ETL Data Pipeline With Advanced Transformations
Introduction
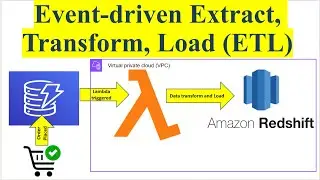
Opening: The video starts with an introduction to AWS Glue, highlighting its capabilities as a serverless ETL (Extract, Transform, Load) service that simplifies the process of preparing and loading data for analytics.
Objective: The presenter outlines the goal of the video: to demonstrate how to build an advanced ETL data pipeline using AWS Glue, incorporating sophisticated data transformations.
Part 1: Overview of AWS Glue
Service Explanation: Brief overview of AWS Glue, including its components like Glue Data Catalog, Glue Crawlers, and Glue Jobs.
Use Cases: Examples of scenarios where AWS Glue can be effectively used, such as data warehousing, real-time analytics, and big data processing.
Part 2: Setting Up the Environment
AWS Account Setup: Instructions on setting up an AWS account and configuring necessary permissions.
IAM Roles: Explanation on creating and assigning IAM roles to Glue services for accessing data sources and destinations securely.
Part 3: Creating a Glue Crawler
Data Source Connection: Demonstrating how to connect to a data source (e.g., an S3 bucket) where raw data is stored.
Crawler Configuration: Step-by-step process to configure a Glue Crawler to scan the data source and populate the Glue Data Catalog with metadata.
Running the Crawler: Execution of the crawler and verification of the metadata in the Glue Data Catalog.
Part 4: Developing Glue ETL Jobs
Job Creation: How to create a new Glue ETL job using the AWS Management Console.
Script Editor: Introduction to the script editor within Glue, where ETL scripts are written in Python or Scala.
Job Configuration: Setting up job parameters, including input and output data locations, and specifying the script to use.
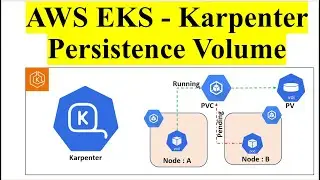
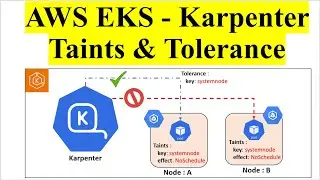
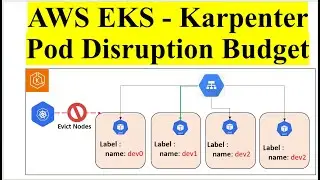
Part 5: Advanced Transformations
Transformations Overview: Explanation of various data transformations that can be performed within Glue, such as data filtering, mapping, and aggregation.
Part 6: Loading Transformed Data
Data Destination: Configuring the final destination for the transformed data, such as an S3 bucket, Amazon Redshift, or an RDS instance.
Loading Process: Steps to load the transformed data into the destination and verify its integrity.
Repo Link : https://github.com/RekhuGopal/PythonH...
#aws #etl #glue #cloudquicklabs #datatransformation #dataengineering #data #aws
#awscloud
#awsglue
#glueetl
#dataengineering
#datapipeline
#etl
#cloudcomputing
#bigdata
#datascience
#dataanalytics
#serverless
#awstutorial
#cloudtutorial
#awsetl
#datatransformation
#advancedetl
#pythonetl
#scalacode
#clouddata
#automation
#datavalidation
#dataquality
#awscrawler
#gluecrawler
#gluejob
#datawarehouse
#amazonredshift
#s3
#awsrds
#dataintegration
#datawrangling
#dataprocessing
#cloudetl
#awstrigger
#workflowautomation
#cloudstorage
#dataaggregation
#datafiltering
#datamapping
#awssecurity
#awspermissions
#iamroles
#datasource
#datadestination
#awsmanagementconsole
#cloudservices
#cloudsolutions
#awssolutions
#cloudarchitecture
#cloudplatform
#clouddataengineering
#etlworkflow
#datasynchronization
#datapreparation
#cloudintegration

![[FREE] SLIMESITO x BEEZYB TYPE BEAT 2022 -](https://images.videosashka.com/watch/1EoTITwenvE)