ETL | AWS Glue | Spark DataFrame | Working with PySpark DataFrame in | AWS Glue Notebook Job
===================================================================
1. SUBSCRIBE FOR MORE LEARNING :
/ @cloudquicklabs
===================================================================
2. CLOUD QUICK LABS - CHANNEL MEMBERSHIP FOR MORE BENEFITS :
/ @cloudquicklabs
===================================================================
3. BUY ME A COFFEE AS A TOKEN OF APPRECIATION :
https://www.buymeacoffee.com/cloudqui...
===================================================================
The video titled "Working with PySpark DataFrame in | AWS Glue Notebook Job" provides a comprehensive guide on loading Jupyter Notebook files (.ipynb) and working with Spark DataFrames to build data pipelines in AWS Glue. Here’s a generic description of the content covered in the video:
Introduction to AWS Glue and PySpark:
The video begins with an introduction to AWS Glue, explaining its role as a managed ETL (Extract, Transform, Load) service, and how it integrates with PySpark, the Python API for Apache Spark, for big data processing.
Loading Jupyter Notebooks:
It demonstrates how to load and run Jupyter Notebook files within the AWS Glue environment. This includes setting up the notebook, importing necessary libraries, and initializing the Spark session.
Creating and Manipulating DataFrames:
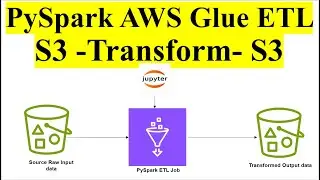
The tutorial covers the creation of PySpark DataFrames from various data sources. It shows how to read data from AWS S3, perform data transformations such as filtering, aggregations, and joins, and write the transformed data back to storage.
Building Data Pipelines:
The core focus is on constructing data pipelines. The video explains each stage of the pipeline, from data extraction and cleaning to transformation and loading. Each stage is verified step-by-step to ensure the correctness and efficiency of the pipeline.
Stage-by-Stage Verification:
Detailed guidance is provided on how to verify the results at each stage of the pipeline. This includes printing schema and sample data, checking transformation results, and ensuring data integrity before proceeding to the next stage.
Practical Examples and Hands-On Demos:
Throughout the video, practical examples and hands-on demonstrations are shown to illustrate the concepts. This helps viewers to see the real-time application of PySpark operations within AWS Glue notebooks.
Conclusion and Best Practices:
The video concludes with best practices for working with PySpark in AWS Glue, tips for optimizing ETL jobs, and managing costs effectively.
repo link : https://github.com/RekhuGopal/PythonH...
00:04 Creating an ETL job using PySpark DataFrame in AWS Glue Notebook
02:06 Understanding Pyspark DataFrame in AWS Glue Notebook Job
04:03 Working with PySpark DataFrame in AWS Glue
05:54 Working with PySpark DataFrame in AWS Glue Notebook Job
07:53 AWS Glue job created a DataFrame from raw data and printed schema for analysis
09:50 Converting CSC file to Parquet file in AWS Glue Notebook Job
11:36 Understanding DataFrame functionality in PySpark on AWS Glue
13:24 Performing advanced operations on PySpark DataFrame in AWS Glue Notebook Job
15:11 Overview of operations on Spark DataFrame using AWS Glue Notebook Job
#aws
#awsglue
#pyspark
#dataframe
#notebook
#jupyter
#etl
#bigdata
#datapipeline
#spark
#datascience
#dataprocessing
#tutorial
#howto
#dataengineering
#cloud
#amazonwebservices
#machinelearning
#datatransformation
#s3
#sparkjob
#gluejob
#automation
#datacleaning
#dataanalysis
#dynamicframe
#python
#datasciencetutorial
#dataengineeringtutorial
#pysparktutorial
#awsgluetutorial