Efficient Deep Learning of Robust Policies from MPC via Imitation and Tube-Guided Data Augmentation
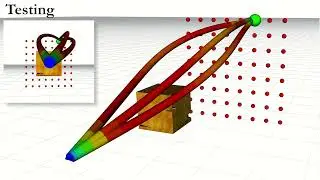
In this work, we propose an Imitation Learning strategy to efficiently compress a computationally expensive MPC into a deep neural network policy that is robust to previously unseen disturbances.
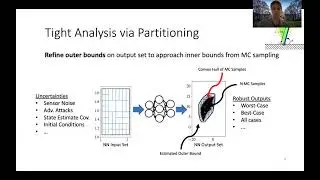
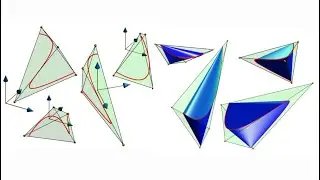
By using a robust variant of the MPC, called Robust Tube MPC, and leveraging properties from the controller, we introduce computationally-efficient data augmentation methods that enable a significant reduction of the number of MPC demonstrations and training efforts required to generate a robust policy.
Our approach opens the possibility of zero-shot transfer of a policy trained from a single MPC demonstration collected in a nominal domain, such as a simulation or a robot in a lab/controlled environment, to a new domain with previously unseen bounded model errors/perturbations.
Numerical evaluations performed using linear and nonlinear MPC for agile flight on a multirotor show that our method outperforms strategies commonly employed in IL (such as Dataset-Aggregation (DAgger) and Domain Randomization (DR)) in terms of demonstration-efficiency, training time, and robustness to perturbations unseen during training. Experimental evaluations validate the efficiency and real-world robustness.
Arxiv: https://arxiv.org/abs/2306.00286
Accepted to the IEEE Transactions on Robotics (T-RO) 2024.
Interested to know more? Check out our related work:
Tube-NeRF: Efficient learning of vision-based policies: • Tube-NeRF: Efficient Imitation Learni...
SAMA: Efficient learning of adaptive policies: • Experimental Results for "Efficient L...











![[ICRA24] PUMA: Decentr. Uncertainty-aware Multiagent Traj. Planner w/ Image Segmentation Frame Align](https://images.videosashka.com/watch/W73p42XRcaQ)
![[Presentation] Deep-PANTHER: Learning-Based Perception-Aware Traj. Planner in Dynamic Environments](https://images.videosashka.com/watch/zlMxuSSvo3o)