Rapid Prototyping In Data Science With Big Data & Python
David Ziganto
http://pyohio.org/schedule/presentati...
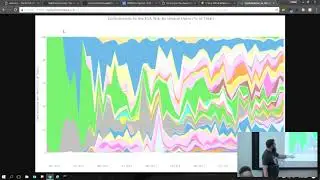
Rapid prototyping in data science often hits a wall when data is too large to fit into memory. When this happens, teams are often confronted with two options: sampling techniques or porting to Apache Spark. Both have significant drawbacks. In this talk, I'll demonstrate how to leverage Dask and Scikit-learn to solve this problem.
PyOhio is a free (thanks sponsors!) annual conference for Python programmers in and around Ohio and the entire Midwest.
http://pyohio.org/

















![[Peninsula] "Structured Authoring to Set Your Content Free" at Genesys](https://images.videosashka.com/watch/INr38MCQjeM)