I don t parse with selenium just get me the html
на канале: CodeRift
Get Free GPT4o from https://codegive.com
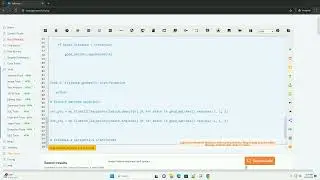
certainly! when using selenium to retrieve the html content of a webpage without parsing it, you can simply extract the whole html source code. this can be useful for scenarios where you need to save the webpage content for later analysis or processing.
below is a step-by-step guide along with a code example in python using selenium to achieve this:
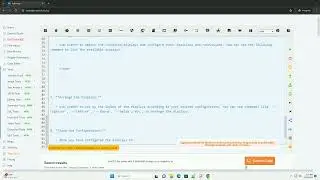
step 1: install selenium
if you haven't already installed the selenium library, you can do so using pip:
step 2: install a webdriver
you will also need to download a webdriver compatible with the browser you want to use. for example, if you are using chrome, download the chromedriver from [here](https://sites.google.com/a/chromium.o....
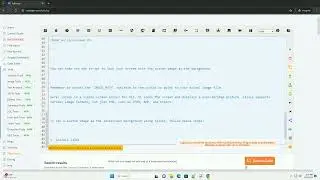
step 3: write the python code
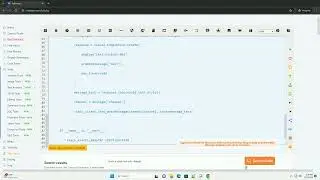
here is an example python code snippet using selenium to retrieve the html content of a webpage without parsing it:
step 4: run the python script
save the code snippet in a python file, replace the `/path/to/chromedriver` with the actual path to your chromedriver executable, and run the script. the html content of the webpage will be printed to the console.
conclusion
by following the steps and the provided code example, you can use selenium to extract the html content of a webpage without parsing it. this can be a useful technique when you need to work with the raw html data for various purposes.
...
#python don't escape backslash
#python don't print warnings
#python don't write bytecode
#python download
#python donut
python don't escape backslash
python don't print warnings
python don't write bytecode
python download
python donut
python don't print new line
python don't buffer stdout
python donut chart
python donut code
python html parser
python html escape
python html2text
python html to pdf
python html
python html template
python html to text
python html library
python html to markdown