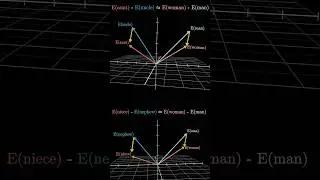
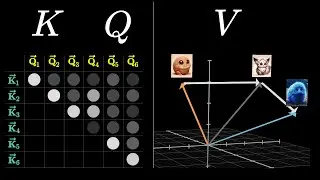
Attention in transformers, visually explained | Chapter 6, Deep Learning
Demystifying attention, the key mechanism inside transformers and LLMs.
Instead of sponsored ad reads, these lessons are funded directly by viewers: https://3b1b.co/support
Special thanks to these supporters: https://www.3blue1brown.com/lessons/a...
An equally valuable form of support is to simply share the videos.
Demystifying self-attention, multiple heads, and cross-attention.
Instead of sponsored ad reads, these lessons are funded directly by viewers: https://3b1b.co/support
The first pass for the translated subtitles here is machine-generated, and therefore notably imperfect. To contribute edits or fixes, visit https://translate.3blue1brown.com/
And yes, at 22:00 (and elsewhere), "breaks" is a typo.
------------------
Here are a few other relevant resources
Build a GPT from scratch, by Andrej Karpathy
• Let's build GPT: from scratch, in cod...
If you want a conceptual understanding of language models from the ground up, @vcubingx just started a short series of videos on the topic:
• What does it mean for computers to un...
If you're interested in the herculean task of interpreting what these large networks might actually be doing, the Transformer Circuits posts by Anthropic are great. In particular, it was only after reading one of these that I started thinking of the combination of the value and output matrices as being a combined low-rank map from the embedding space to itself, which, at least in my mind, made things much clearer than other sources.
https://transformer-circuits.pub/2021...
Site with exercises related to ML programming and GPTs
https://www.gptandchill.ai/codingprob...
History of language models by Brit Cruise, @ArtOfTheProblem
• ChatGPT: 30 Year History | How AI Lea...
An early paper on how directions in embedding spaces have meaning:
https://arxiv.org/pdf/1301.3781.pdf
------------------
Timestamps:
0:00 - Recap on embeddings
1:39 - Motivating examples
4:29 - The attention pattern
11:08 - Masking
12:42 - Context size
13:10 - Values
15:44 - Counting parameters
18:21 - Cross-attention
19:19 - Multiple heads
22:16 - The output matrix
23:19 - Going deeper
24:54 - Ending
------------------
These animations are largely made using a custom Python library, manim. See the FAQ comments here:
https://3b1b.co/faq#manim
https://github.com/3b1b/manim
https://github.com/ManimCommunity/manim/
All code for specific videos is visible here:
https://github.com/3b1b/videos/
The music is by Vincent Rubinetti.
https://www.vincentrubinetti.com
https://vincerubinetti.bandcamp.com/a...
https://open.spotify.com/album/1dVyjw...
------------------
3blue1brown is a channel about animating math, in all senses of the word animate. If you're reading the bottom of a video description, I'm guessing you're more interested than the average viewer in lessons here. It would mean a lot to me if you chose to stay up to date on new ones, either by subscribing here on YouTube or otherwise following on whichever platform below you check most regularly.
Mailing list: https://3blue1brown.substack.com
Twitter: / 3blue1brown
Instagram: / 3blue1brown
Reddit: / 3blue1brown
Facebook: / 3blue1brown
Patreon: / 3blue1brown
Website: https://www.3blue1brown.com