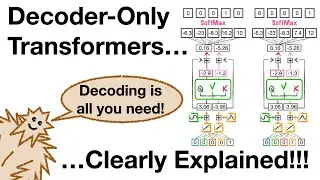
Decoder-Only Transformers, ChatGPTs specific Transformer, Clearly Explained!!!
Transformers are taking over AI right now, and quite possibly their most famous use is in ChatGPT. ChatGPT uses a specific type of Transformer called a Decoder-Only Transformer, and this StatQuest shows you how they work, one step at a time. And at the end (at 32:14), we talk about the differences between a Normal Transformer and a Decoder-Only Transformer. BAM!
NOTE: If you're interested in learning more about Backpropagation, check out these 'Quests:
The Chain Rule: • The Chain Rule
Gradient Descent: • Gradient Descent, Step-by-Step
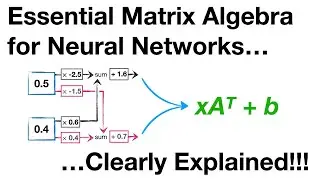
Backpropagation Main Ideas: • Neural Networks Pt. 2: Backpropagatio...
Backpropagation Details Part 1: • Backpropagation Details Pt. 1: Optimi...
Backpropagation Details Part 2: • Backpropagation Details Pt. 2: Going ...
If you're interested in learning more about the SoftMax function, check out:
• Neural Networks Part 5: ArgMax and So...
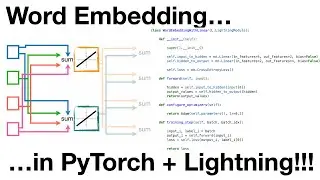
If you're interested in learning more about Word Embedding, check out: • Word Embedding and Word2Vec, Clearly ...
If you'd like to learn more about calculating similarities in the context of neural networks and the Dot Product, check out:
Cosine Similarity: • Cosine Similarity, Clearly Explained!!!
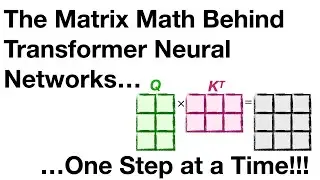
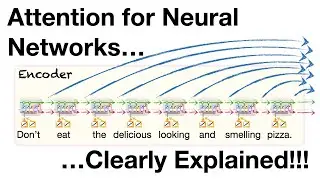
Attention: • Attention for Neural Networks, Clearl...
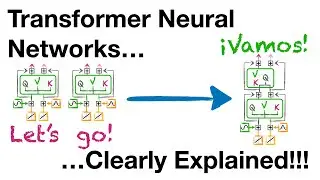
If you'd like to learn more about Normal Transformers, see: • Transformer Neural Networks, ChatGPT'...
If you'd like to support StatQuest, please consider...
Patreon: / statquest
...or...
YouTube Membership: / @statquest
...buying my book, a study guide, a t-shirt or hoodie, or a song from the StatQuest store...
https://statquest.org/statquest-store/
...or just donating to StatQuest!
paypal: https://www.paypal.me/statquest
venmo: @JoshStarmer
Lastly, if you want to keep up with me as I research and create new StatQuests, follow me on twitter:
/ joshuastarmer
0:00 Awesome song and introduction
1:34 Word Embedding
7:26 Position Encoding
10:10 Masked Self-Attention, an Autoregressive method
22:35 Residual Connections
23:00 Generating the next word in the prompt
26:23 Review of encoding and generating the prompt
27:20 Generating the output, Part 1
28:46 Masked Self-Attention while generating the output
30:40 Generating the output, Part 2
32:14 Normal Transformers vs Decoder-Only Transformers
#StatQuest