code https://github.com/soumilshah1995/cod...
БИТВА ЗА 1 млн рублей. Легендарный Титульный Вторник! #1 ПОПЫТКА
Jharkhand e-Kalyan Scholarship 2021-22 | E-Kalyan Scholarship 2021 | Scholarship Applying Date 2021
STYLOPHONE GEN-X1 & STYLOPHONE BEAT & STYLOPHONE THEREMIN - TFM 250208
in real life am a serious person check on social media 🤣🤣💔
Joe Rogan & Bobby Lee on Israel and Palestine
6 Dicas Top como Criar Vídeo de Alta Qualidade para Influenciadores do Youtube
Ava Max - TME Live Concert 2021 (Full Performance HD)
MIXTAPE COVER DESIGNED IN PHOTOSHOP CC (SJCGFX Works)
Quick Getting Started with Iceberg on Glue Notebook: Insert, Deletes, and Merge INTO Commands
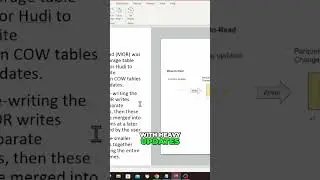
Optimizing Data Storage with Hudi's MOR Table Type
Exciting New YouTube Video Complete Project Walkthrough with All the Details!
#1 Mastering Trino and Kubernetes: Easy Steps for Local Installation and Configuration
Mastering PySpark and Glue Your Ultimate Guide to Data Transformation and ETL
#2 Maximize Your Productivity: 2 Habits for a More Successful Day
How to use SparkSQL to Create Hudi Tables on AWS Glue | Hands on
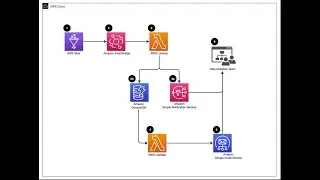
SNS + Lambda: How to Trigger Lambda Functions from SNS using Message Filtering
How to Query Hudi Tables in Incremental Fashion and Get only New data on AWS Glue | Hands on Lab
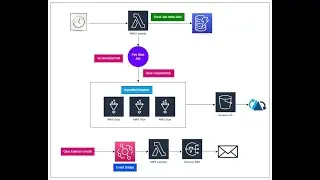
Automate alerting and reporting for AWS Glue job resource usage
How to Set Up AWS Glue Locally with Docker: Accessing Glue Database & Table in Your LocalEnvironment
Mastering File Sizing in Hudi: Boosting Performance and Efficiency
EMR Serverless Made Easy: Submitting Hive SQL Queries for Beginners with NYC Taxi Dataset
EMR Serverless for Beginners: | Ingest Data incrementally | Submit Spark Job with EMR-CLI |Data lake
Maximizing Efficiency DataLake(Hudi) Glue ETL Jobs with Templated Approach &Serverless Architecture
How to Build Your Own Version of AWS Glue Bookmark to get Only New Incremental Files
Build, deploy, and run Spark jobs on Amazon EMR with the open-source EMR CLI tool
Efficiently Managing Ride & Late Arriving Tips Data with Incremental ETL using Apache Hudi :Hands On
Joining Hudi Raw Tables for Powerful Data Analysis with Spark SQL
April 22, 2023
Effortlessly Sync Your JDBC Source to Hudi Transactional Datalake: No DMS or Debezium Required!
Unlocking Incremental Data in PySpark: Extracting from JDBC Source without Debezium or AWS DMS (CDC)
Step-by-Step Guide to Incrementally Pulling Data from JDBC with Python and PySpark
How to Stay Motivated to Learn New Things: Tips and Strategies