Scale and Optimize Data Engineering Pipelines with Best Practices: Modularity and Automated Testing
In rapidly changing conditions, many companies build ETL pipelines using ad-hoc strategy. Such an approach makes automated testing for data reliability almost impossible and leads to ineffective and time-consuming manual ETL monitoring.
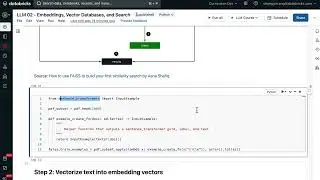
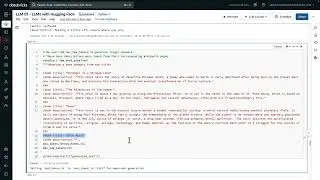
Software engineering decouples code dependency, enables automated testing, and powers engineers to design, deploy, and serve reliable data in a module manner. As a consequence, the organization is able to easily reuse and maintain its ETL code base.
In this presentation, we discuss the challenges data engineers face when it comes to data reliability. Furthermore, we demonstrate how software engineering best practices help to build code modularity and automated testings for modern data engineering pipelines.
What you’ll learn:
– Software engineering best practices in ETL projects: design patterns and modularity
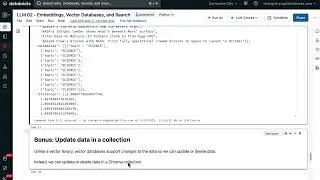
– Automate ETL testings for data reliability: unit test, functional test, and end2end test.
About:
Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Read more here: https://databricks.com/product/unifie...
See all the previous Summit sessions:
Connect with us:
Website: https://databricks.com
Facebook: / databricksinc
Twitter: / databricks
LinkedIn: / databricks
Instagram: / databricksinc Databricks is proud to announce that Gartner has named us a Leader in both the 2021 Magic Quadrant for Cloud Database Management Systems and the 2021 Magic Quadrant for Data Science and Machine Learning Platforms. Download the reports here. https://databricks.com/databricks-nam...