116 тысяч подписчиков
3 тысяч видео
The Databricks Lakehouse for Manufacturing
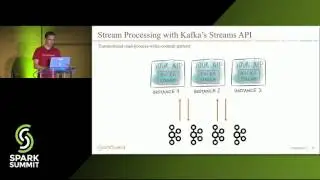
Building a Streaming Microservice Architecture: with Apache Spark Structured Streaming and Friends
Bucketing in Spark SQL 2 3 with Jacek Laskowski
Using Open Source Tools to Build Privacy-Conscious Data Systems
Unlocking Near Real Time Data Replication with CDC, Apache Spark™ Streaming, and Delta Lake
Creating, Weaponizing, and Detecting Deep Fakes | Hany Farid | Keynote Spark + AI Summit 2020
Apache Spark and Sights at Speed: Streaming, Feature Management, and ExecutionTed Malaska Capital On
Introducing Exactly Once Semantics in Apache Kafka with Matthias J. Sax
Machine Learning with PyCaret
Architect’s Open-Source Guide for a Data Mesh Architecture
Databricks Connect Powered by Spark Connect: Develop and Debug Spark From Any Developer Tool
Apache Spark Performance Troubleshooting at Scale, Challenges, Tools, and Methods with Luca Canali
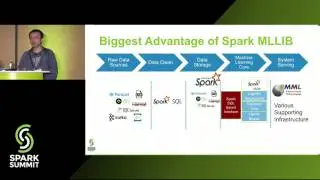
Apache Spark MLlib's Past Trajectory and New Directions - Joseph Bradley
Building Robust ETL Pipelines with Apache Spark - Xiao Li
Discover the Data Lakehouse
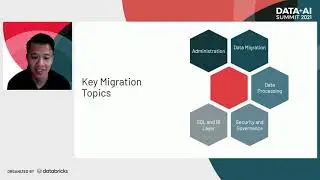
Clean Your Data Swamp by Migrating Off of Hadoop
Introducing the Next Generation Data Science Workspace | Keynote Spark + AI Summit 2020
Building a Unified Data Pipeline with Apache Spark and XGBoost with Nan Zhu
Hybrid Apache Spark Architecture with YARN and Kubernetes
From Idea to Model: Productionizing Data Pipelines with Apache Airflow
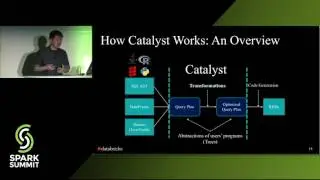
A Deep Dive into Spark SQL's Catalyst Optimizer with Yin Huai
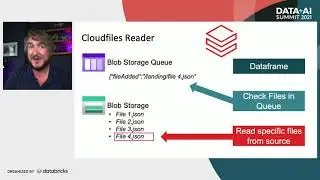
Accelerating Data Ingestion with Databricks Autoloader
Managing Data Encryption in Apache Spark™
LLM Module 4: Fine-tuning and Evaluating LLMs | 4.2 Module Overview
LLM Module 4: Fine-tuning and Evaluating LLMs | 4.3 Applying Foundation LLMs
Accelerate Your ML Pipeline with AutoML and MLflow
LLM Module 2 - Embeddings, Vector Databases, and Search | 2.2 Module Overview
Simplifying Change Data Capture using Databricks DeltaDr Ameet Kini Databricks
Tutorial - Getting Started with Databricks Repos | Databricks Academy
LLM Module 4: Fine-tuning and Evaluating LLMs | 4.4 Fine Tuning: Few-shot Learning
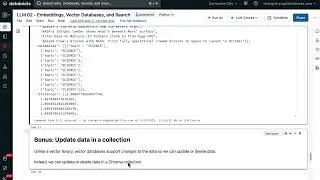
LLM Module 2 - Embeddings, Vector Databases, and Search | 2.5 Vector Stores
Scale and Optimize Data Engineering Pipelines with Best Practices: Modularity and Automated Testing
Driving Real-Time Data Capture and Transformation in Delta Lake with Change Data Capture
Scaling Python for Data Science Using Apache Spark (Garren Staubli)
Simplify Data Conversion from Spark to TensorFlow and PyTorch
LLM Module 6: LLMOps | 6.7 Notebook Demo
LLM Module 4: Fine-tuning and Evaluating LLMs | 4.1 Introduction
A Journey to Building an Autonomous Streaming Data Platform—Scaling to Trillion Events Monthly
LLM Module 2 - Embeddings, Vector Databases, and Search | 2.3 How does Vector Search work
LLM Module 2 - Embeddings, Vector Databases, and Search | 2.1 Introduction
LLM Module 4: Fine-tuning and Evaluating LLMs | 4.10 Task specific Evaluations
LLM Module 2 - Embeddings, Vector Databases, and Search | 2.8.2 Notebook Demo Part 2
LLM Module 2 - Embeddings, Vector Databases, and Search | 2.6 Best Practices
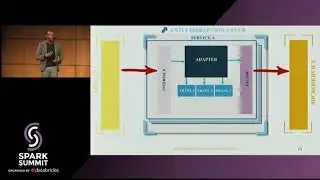
Responsible AI: Protecting Privacy and Preserving Confidentiality in ML and Data Analytics
Building a Better Delta Lake with Talend and Databricks
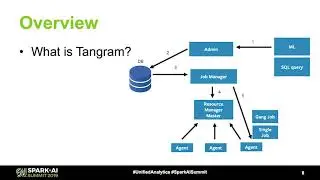
Tangram Distributed Scheduling Framework for Apache Spark at Facebook
Building a Business Logic Translation Engine with Spark Streaming for Communicating -Patrick Bamba
Prompt Engineering is Dead; Build LLM Applications with DSPy Framework
Real-Time Forecasting at Scale using Delta Lake and Delta Caching
LLM Module 3 - Multi-stage Reasoning | 3.7.1 Notebook Demo Part 1
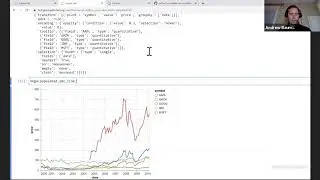
Encoding multi-layered Vega-Lite COVID-19 Geodata visualizations