Apache Kafka® Cluster Scaling and Automation
https://cnfl.io/kafka-internals-101-m... | With Apache Kafka®, cluster balancing and scaling is a crucial part of running distributed systems, but it can be tricky to handle. Luckily for you, there are tools, tips, and tricks to help with this!
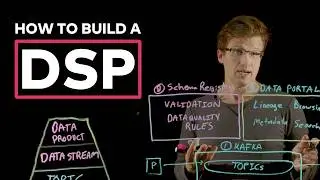
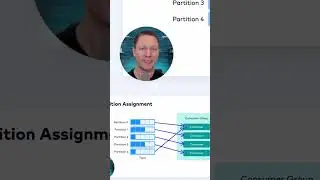
Get an overview of automatic cluster scaling and Self-Balancing Clusters for Apache Kafka, as well as operational tools such as `kafka-reassign-partitions.sh` and the Confluent Auto Data Balancer. Jun Rao (Kafka Committer, PMC Member, VP of Kafka, and Co-Founder, Confluent) explains that because Kafka is designed as a distributed system if resource needs change, the easiest way to address this is by adding or removing brokers. In either case, existing data needs to be redistributed to keep a cluster balanced.
Use the promo code INTERNALS101 to get $25 of free Confluent Cloud usage: https://www.confluent.io/confluent-cl...
Promo code details: https://www.confluent.io/confluent-cl...
LEARN MORE
► Auto-Balancing and Optimizing Apache Kafka Clusters with Improved Observability and Elasticity in Confluent Platform 7.0: https://www.confluent.io/blog/auto-ba...
ABOUT CONFLUENT
Confluent is pioneering a fundamentally new category of data infrastructure focused on data in motion. Confluent’s cloud-native offering is the foundational platform for data in motion – designed to be the intelligent connective tissue enabling real-time data, from multiple sources, to constantly stream across the organization. With Confluent, organizations can meet the new business imperative of delivering rich, digital front-end customer experiences and transitioning to sophisticated, real-time, software-driven backend operations. To learn more, please visit www.confluent.io.
#streamprocessing #apachekafka #kafka #confluent