How to Get Your Data Ready for AI Agents (Docs, PDFs, Websites)
Want to get started as a freelancer? Let me help: https://www.datalumina.com/data-freel...
Additional Resources
📚 Just getting started? Learn the fundamentals of AI: https://www.skool.com/data-alchemy
🚀 Already building AI apps? Get our production framework: https://launchpad.datalumina.com/?utm...
💼 Need help with a project? Work with me: https://www.datalumina.com/solutions?...
🔗 GitHub Repository
https://github.com/daveebbelaar/ai-co...
🛠️ My VS Code / Cursor Setup
• The Ultimate VS Code Setup for Data &...
⏱️ Timestamps
0:45 Building an Extraction Pipeline
2:15 Document Conversion Basics
6:12 HTML Extraction Techniques
9:10 Chunking Data for AI
14:22 Storing in Vector Databases
19:51 Searching the Vector Database
22:16 Creating an Interactive Application
📌 Description
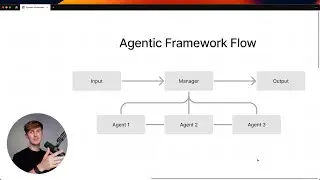
In this Docling tutorial, you will learn to extract and structure data from various documents, utilizing techniques such as parsing, chunking, and embedding. A walkthrough of Docling and a practical demonstration illustrate these processes.
The video also explores integrating vector databases for efficient data storage and enhancing AI responses through embedding models. Finally, a simple interactive chat application is demonstrated, showcasing the completed knowledge extraction pipeline and optimization strategies.
👋🏻 About Me
Hi! I'm Dave, AI Engineer and founder of Datalumina®. On this channel, I share practical tutorials that teach developers how to build production-ready AI systems that actually work in the real world. Beyond these tutorials, I also help people start successful freelancing careers. Check out the links above to learn more!