Why Serverless Flink Matters - Blazing Fast Stream Processing Made Scalable
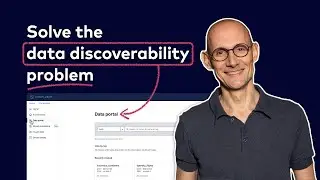
The shift from batch processing to real-time processing of data is accelerating. Building real-time data applications is a necessity for many businesses as customers expect data to be always up-to-date and their apps to react to changes as they happen. However building and productizing real-time applications is often a complex and lengthy process due to limited serverless options to build such apps.
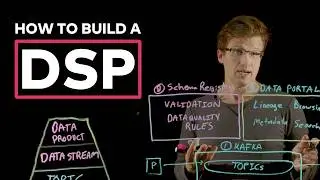
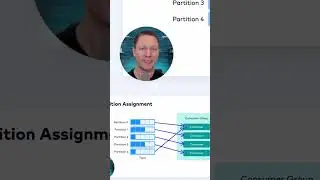
The introduction of AWS lambdas was a watershed moment in the world of cloud computing. It allowed developers to fire up “fully-managed” computer programs while paying for only when the program ran. Serverless compute comes with three big advantages - improved scalability, reduced cost, and increased flexibility. We’re bringing this same powerful paradigm to real time data processing with Flink in Confluent Cloud. Using this model, users can focus on writing business logic instead of managing nodes and other infrastructure.
Attendees will learn the benefits of serverless and see how it fits into the context of stream processing. We’ll then kick off a demo where we’ll focus on a real world production use case that uses Flink jobs to power an application with extremely low latency.
ABOUT CONFLUENT
Confluent is pioneering a fundamentally new category of data infrastructure focused on data in motion. Confluent’s cloud-native offering is the foundational platform for data in motion – designed to be the intelligent connective tissue enabling real-time data, from multiple sources, to constantly stream across the organization. With Confluent, organizations can meet the new business imperative of delivering rich, digital front-end customer experiences and transitioning to sophisticated, real-time, software-driven backend operations. To learn more, please visit www.confluent.io.
#confluent #apachekafka #kafka