Error when trying to extract text from PDF using Python PDFMINER
Download this code from https://codegive.com
Title: Handling Errors when Extracting Text from PDF using Python PDFMiner
Introduction:
PDFMiner is a powerful library in Python for extracting text, images, and metadata from PDF files. However, like any tool, it may encounter errors under certain circumstances. In this tutorial, we'll explore common errors that may occur when extracting text from PDFs using PDFMiner and discuss how to handle them effectively.
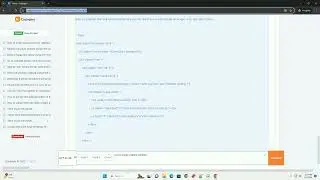
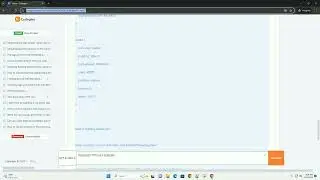
Make sure you have Python installed on your system. You can install PDFMiner using the following command:
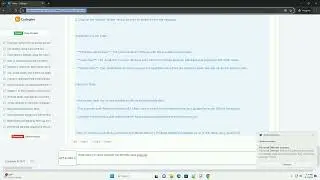
This error occurs when the specified PDF file cannot be found. Ensure that the file path is correct.
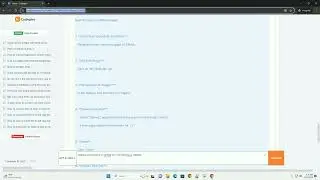
PDF files can sometimes have syntax errors. Handle them gracefully.
If a PDF is password-protected, you need to handle the password error.
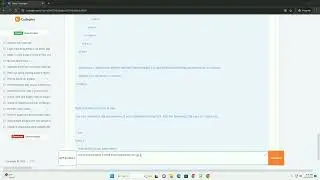
Handle generic exceptions to capture unforeseen issues.
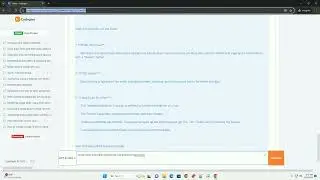
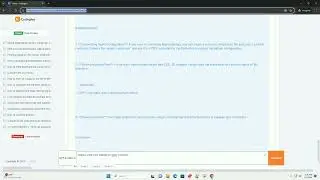
By incorporating these error-handling strategies, you can make your PDF text extraction script more robust and resilient to various issues that might arise during the process. Always remember to check the PDFMiner documentation for the latest updates and additional information: PDFMiner Documentation.
Feel free to customize the code examples based on your specific use case and requirements.
ChatGPT